Restic Backups with systemd and Prometheus exporter
In this blog post I describe the workflow I currently use to create offsite backups of my servers. This post has been in the making for a while. I started writing the first version of it at the beginning of 2019. Now, two years later the setup has evolved into a shape where I feel comfortable sharing it.
The core of the setup is the excellent restic: a simple yet powerful tool to create remote backups. It supports snapshots and saves the data in a content-addressable storage format which makes it very bandwidth- and space-efficient. Thus it is also quite fast. Another nice feature of restic is also that it supports dozens of backends for storing data. Personally, I’m using the Backblaze B2 backend.
# Table of Contents
- Main backup script
- Deleting old data
- Periodic backups with systemd timer
- Reporting failures
- Prometheus exporter
- Grafana dashboard
# Main backup script
Restic can be configured entirely through environment variables, so I have a file which contains just these configuration variables and can be sourced by other scripts (/etc/restic-env.sh).
This file needs to have very strict permissions (e.g. 0600)!
| |
Next up, there is the main backup script (/usr/local/sbin/restic-backup.sh):
| |
The script first checks if the repository is already present on the remote site or if its needs to be created. Afterwards restic checks the repository for any errors. Finally, we create a new snapshot by running the restic backup command.
This setup is already sufficient to do basic, one-off backups (from a laptop for example). For a server however, a bit more automation is required.
# Deleting old data
First of all, “local” backups need to be cleaned up.
For example, I have several database backup jobs which daily create database snapshots under /var/backups/DB-NAME_YYYY-MM-DD-HH-MM.sql.gz.
Since I don’t want to keep these around forever (and they certainly don’t need to be remotely backed up forever), I am removing those before running the main backup script:
/usr/local/sbin/cleanup-backups.sh:
| |
Next up, old snapshots need to be expired from the repository (though it is also possible to treat the remote backend as a write-only store, i.e. never deleting anything from the remote).
For this purpose, I have the following script at /usr/local/sbin/restic-prune.sh:
| |
This script loads the restic configuration, checks the repository for errors and then – once a week – deletes old snapshots according to a pattern and removes old data (prune). Deleting old snapshots is a very lightweight operation since it only needs to remove the snapshots IDs from an index. The garbage collection (deleting old data) however is more compute- and bandwidth-intensive and for this reason is only performed once a week.
# Periodic backups
Running backups needs to be automated and performed regularly. Back in the day cronjobs were used for this purpose, nowadays we can use systemd timers.
| |
The nice thing about systemd timers is that they are a lot more flexible than traditional cronjobs.
For example, it is possible to specify multiple run times for them (e.g. at noon, at midnight and on reboot) without duplication.
It also makes it really simple to randomly delay the execution of units (see RandomizedDelaySec above).
This is helpful when you have multiple servers backing up to the same backend, so not all servers run it at the same time and the backend does not get overloaded.
Additionally, we get the logging properties of journald for free, which we take advantage of later on.
Finally, by using timers systemd gives us helpful diagnostic information, such as when the timer was last activated and when it is going to be activated next:
$ systemctl status restic-backup.timer
● restic-backup.timer - Activates Backup Job
Loaded: loaded (/etc/systemd/system/restic-backup.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Sun 2021-05-23 12:59:35 CEST; 1 day 5h ago
Trigger: Tue 2021-05-25 01:30:12 CEST; 7h left
$ systemctl list-timers restic-backup.timer
NEXT LEFT LAST PASSED UNIT ACTIVATES
Tue 2021-05-25 01:30:12 7h left Mon 2021-05-24 01:31:39 16h ago restic-backup.timer restic-backup.service
The timer activates a systemd service, so we also need to install a service file:
| |
The service file ties together the cleanup-backups.sh, restic-backup.sh and restic-prune.sh scripts outlined above.
The service is a oneshot service, which indicates to systemd that the main process of this service will exit at some point.
If it exits with return code 0 it is considered successful, otherwise failed.
$ systemctl status restic-backup.service
● restic-backup.service - Run backup job
Loaded: loaded (/etc/systemd/system/restic-backup.service; disabled; vendor preset: enabled)
Active: inactive (dead) since Thu 2021-05-27 01:35:33 CEST; 16h ago
Docs: man:restic(1)
https://restic.readthedocs.io/en/stable/
Process: 27976 ExecStartPre=/usr/local/bin/cleanup-backups.sh (code=exited, status=0/SUCCESS)
Process: 27978 ExecStart=/usr/local/sbin/restic-backup.sh (code=exited, status=0/SUCCESS)
Process: 28403 ExecStartPost=/usr/local/sbin/restic-prune.sh (code=exited, status=0/SUCCESS)
Process: 28642 ExecStartPost=/usr/local/sbin/restic-exporter.sh (code=exited, status=0/SUCCESS)
Main PID: 27978 (code=exited, status=0/SUCCESS)
# Reporting failures
The main backup service file (shown above) specifies an OnFailure directive: another service that will be activated in case the main service fails.
This service file runs the unit-failure.sh script which will send the administrator an email that the service failed.
Having all service logs (since it was last started) immediately available in an email can be very useful to quickly diagnose if the error is fatal (e.g. the main backup routine didn’t run – GO FIX YOUR BACKUP NOW!) or one of the post-processing scripts failed (which can be delayed for some time).
Since systemd is collecting logs for each of the services its running anyway, I use this feature to fetch the logs of the most recent execution.
Additionally, the service will also invoke the restic-exporter.sh script, which we’ll come to next.
| |
/usr/local/sbin/unit-failure.sh:
| |
# Prometheus exporter
The restic-exporter.sh script will analyze the log output of the most recent service invocation.
Unfortunately, I had to resort to parsing the logs directly.
Restic has a stats command (and can even format the data as JSON), but the output is rather confusing and does not contain the kind of information I’m looking for:
$ restic stats --mode=restore-size latest
Stats for the latest snapshot in restore-size mode:
Total File Count: 150845
Total Size: 107.333 GiB
$ restic stats --mode=files-by-contents latest
Stats for the latest snapshot in files-by-contents mode:
Total File Count: 91806
Total Size: 89.275 GiB
$ restic stats --mode=raw-data
Stats for all snapshots in raw-data mode:
Total Blob Count: 288599
Total Size: 107.986 GiB
$ restic stats --mode=blobs-per-file
Stats for all snapshots in blobs-per-file mode:
Total Blob Count: 208486
Total File Count: 107923
Total Size: 114.229 GiB
Instead of using this output, I wrote the following script that parses the restic backup output directly, since this already contains the information I’m looking for (files changed/added, size of current snapshot etc.). After I was done writing it I realized I should probably not have written it in Bash, but it was too late. At least it was a good exercise of defensive Bash programming.
Files: 9 new, 32 changed, 110340 unmodified
Dirs: 0 new, 2 changed, 0 unmodified
Added to the repo: 196.568 MiB
processed 110381 files, 107.331 GiB in 0:36
Of course, this might break with a different restic version, so make sure you test it your environment. I developed this version of the script for restic 0.9.4.
| |
Okay, let’s not look at all that Bash code too long. Instead, here are the raw metrics:
restic_repo_files{unit="restic-backup.service",state="new"} 48
restic_repo_files{unit="restic-backup.service",state="changed"} 36
restic_repo_files{unit="restic-backup.service",state="unmodified"} 110294
restic_repo_size_bytes{unit="restic-backup.service",state="new"} 150428713
restic_repo_dirs{unit="restic-backup.service",state="new"} 0
restic_repo_dirs{unit="restic-backup.service",state="changed"} 2
restic_repo_dirs{unit="restic-backup.service",state="unmodified"} 0
restic_backup_duration_seconds{unit="restic-backup.service",action="backup"} 163
restic_backup_duration_seconds{unit="restic-backup.service",action="cleanup"} 0
restic_backup_duration_seconds{unit="restic-backup.service",action="prune"} 95
restic_backup_failure{unit="restic-backup.service",timestamp="1622072131"} 0
These get picked up by node_exporter’s textfile collector (that’s why they are written to /var/lib/node-exporter/restic-backup.prom), which exposes them to the Prometheus server.
Alternatively, you can also use any other webserver to make the metrics available via HTTP.
Once the metrics are in Prometheus, alertmanager can be used to send alerts to the messaging service of choice.
# Grafana dashboard
What’s still missing? Of course some pretty visualizations!
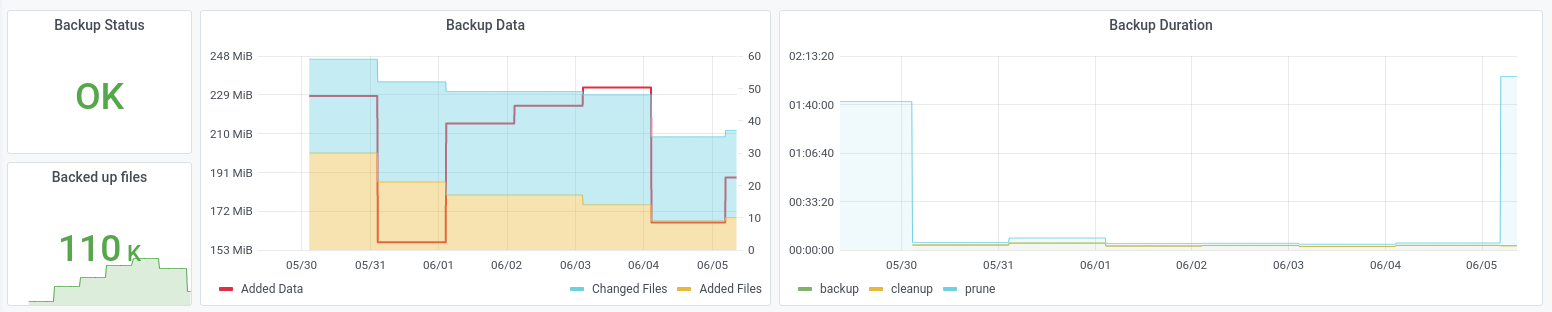
And that’s it! The entire system is quite a beast, but as mentioned at the beginning of this post I have been building it up slowly over the last couple of years and it has been very stable (the most recent addition is the Prometheus exporter).
I recommend restic to anyone who is looking for a backup tool: it’s secure, efficient and rock-solid. If you are just getting started with restic, you might also want to check out autorestic, a CLI wrapper around restic that makes it configurable with YAML files and provides some of the automation I have described above.
Happy backuping restoring!