Troubleshooting too many open files errors in my homelab
Recently I started seeing error messages like the following whenever tailing (following) Kubernetes pod logs in my k3s homelab:
| |
These errors are not just happening inside the Kubernetes environment, but also when I directly SSH onto the host and execute commands, such as:
| |
While I’m running a fairly dense homelab (hosting a lot of different services and containers on the same machine), I was still a bit surprised to see these error messages, especially since they also occur outside of pods and containers.
Today I decided to go and find out what causes these errors.
If you are only interested in the solution, simply skip to the end of this post. Like often times in software engineering, the fix is fairly mundane. If you’re interested in learning a bit about Linux file descriptor limits and troubleshooting them, keep on reading.
# Environment
I’m running a Debian 12 (bookworm) system with Linux kernel 6.1.162 and k3s v1.31.1+k3s1.
# Troubleshooting
First lets check what the file descriptor limit (aka. “number of open files”) inside of a container is:
| |
That’s actually quite a lot!
It appears that in the case of k3s (which uses containerd under the hood), this limit is inherited by the main process.
And k3s has this in the their systemd service unit:
| |
Hmm, interesting. So out-of-the-box each container is allowed to consume the maximum number of file descriptors on the system.
Notably in this case LimitNOFILE=infinity is equivalent to 1048576, because systemd (PID 1) - which spawns the k3s service - itself is only allowed to consume that many fds:
| |
It’s unclear to me where this number for PID 1 comes from (possibly kernel default?), but at this point I’m also pretty certain that this limit is not the issue.
For now, lets try to understand which process or container is allocating this many open file descriptors, with the help of our friends Prometheus and Grafana.
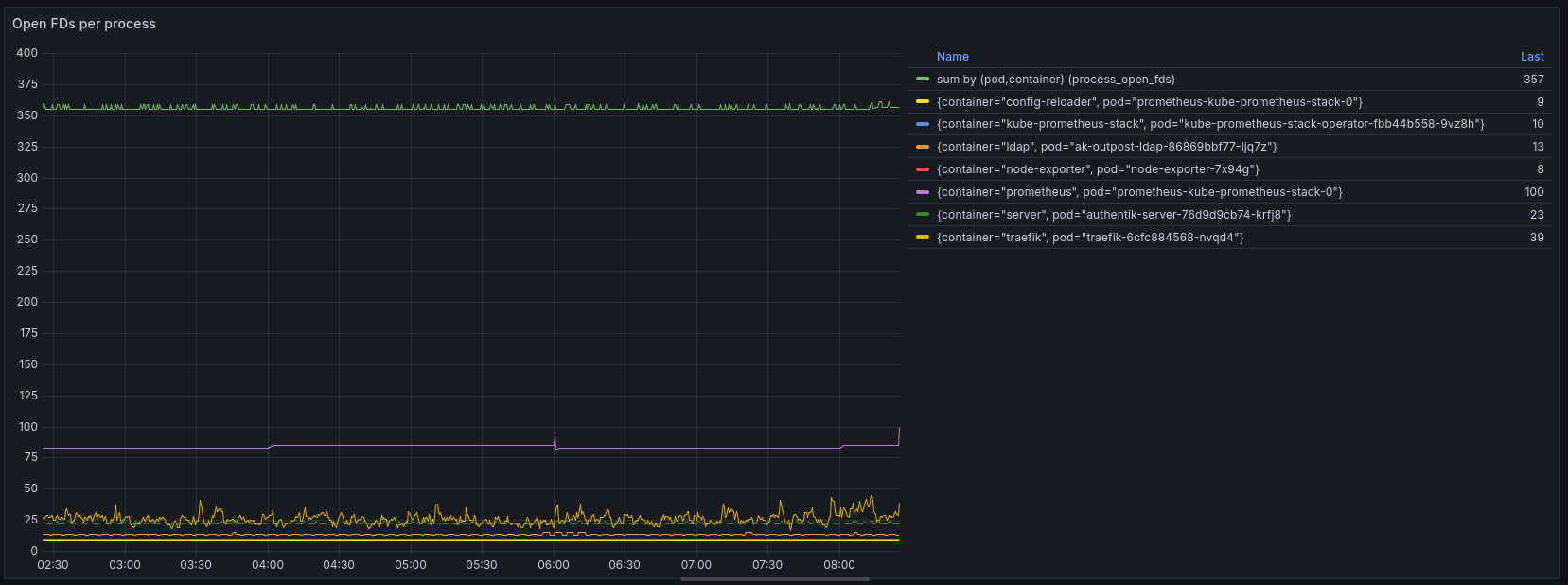
Unfortunately, that does not really help us because the total number of open files captured by this graph is not that high (559), but also because a big chunk of it (357) is not allocated to any container (missing pod / container label on the metric). This indicates that this workload is running outside of k3s.
Let’s put together a small script that evaluates the number of open FDs for each process running the host system.
| |
Output:
| |
This gives us a more complete picture of what’s going on in the system, yet at the same time 7538 total open file descriptors on the system … that should be fine, right? Certainly nowhere near the limit that is set for processes (following is just one example):
| |
We also certainly have not reached the system-wide limit for file descriptors (first column is the current number of open files, last column is the system-wide maximum):
| |
So the number of open files itself does not appear to be an issue, but rather watching/tailing/following output is the problem specifically.
# The real culprit: fsnotify limits
Some research revealed that Linux also has a limit for “fsnotify” watches specifically:
fs.inotify.max_user_watches: max number of filesystem objects that user can watch at oncefs.inotify.max_user_instances: max number of inotify instances that user can createfs.inotify.max_queued_events: max events queued per inotify instance
Let’s check these values:
root@hp-prodesk-g4:~# cat /proc/sys/fs/inotify/max_user_watches
122282
root@hp-prodesk-g4:~# cat /proc/sys/fs/inotify/max_user_instances
128
root@hp-prodesk-g4:~# cat /proc/sys/fs/inotify/max_queued_events
16384
max_user_instances stood out to me - 128 seems a bit low, not?
Especially since usage of inotify (also called fsnotify on other operating systems) is so widespread these days - everything from config reloading, to automatic file discovery, hot reloading and more uses the fsnotify mechanism to achieve this in an efficient manner - this low limit seems really outdated.
Let’s dive a bit deeper into analyzing inotify watches by using this handy inotify-info tool:
| |
Indeed it seems that we are using more than 128 instances, though this is combined across all users. How many inotify instances are there only for the root user?
| |
Aha, there is the smoking gun! The current number of inotify instances for the root user is exactly the same as the maximum! This indicates that we have indeed reached the limit, and therefore are getting errors now.
# The Fix
Let’s raise the limit temporarily:
| |
I’m raising only the max_user_instances limit because it’s the only value that is causing problems (as we have just seen). At the same time, inotify watches are fairly cheap in terms of memory, thus we don’t need to worry about causing excessive memory consumption by raising this limit.
The hard upper bound is controlled by how much kernel memory you are willing or able to dedicate for this use. One inotify watch costs 1080 bytes on 64-bit ones. – https://watchexec.github.io/docs/inotify-limits.html
On OpenShift, the popular enterprise Kubernetes distribution, the value of max_user_instances is set to 8192, hence I’m using the same value (ref 1, ref 2).
On my system, the value of max_user_watches is already quite large (122282) because since Linux kernel 5.11 this value is automatically adjusted based on the available system memory (RAM).
After updating the sysctl value, let’s check if the errors are gone:
| |
Yes, no more “too many open files” errors! I should have focused on “failed to create fsnotify watcher” part of the error message much earlier!
Let’s not forget to make the change persistent (so it will be restored after rebooting):
| |
Happy watching!
# Bonus
As I found out in this post, it’s not only important to keep an eye on the number of open files (file descriptors), but also a specific type of open files: fsnotify / inotify watches. I was wondering if anyone else would like to monitor this metric with node_exporter.
Unfortunately, node_exporter does not report inotify watch counters because this metric is not directly exposed by the kernel (node_exporter issue #866).
Currently, the only way to find out about the number of inotify watches is iterating over all running processes in /proc and examining their open file descriptors to determine the type. This is not acceptable for node_exporter, both in terms of scalability (it becomes very slow when there is a significant number of processes) and security (it requires full root privileges). Several years ago someone even put together a kernel patch to expose this metric directly, but it never got merged.
# References
- https://maestral.app/docs/inotify-limits
- https://unix.stackexchange.com/questions/444998/how-to-set-and-understand-fs-notify-max-user-watches
- https://stackoverflow.com/questions/535768/what-is-a-reasonable-amount-of-inotify-watches-with-linux
- https://watchexec.github.io/docs/inotify-limits.html
- https://anatoly.dev/posts/2025/10/k9s-too-many-open-files/
- https://github.com/mikesart/inotify-info
- https://github.com/prometheus/node_exporter/issues/866
- https://www.man7.org/linux/man-pages/man7/inotify.7.html
- https://en.wikipedia.org/wiki/Inotify